| Chapter 3. Deriving Your Own Module from Module | ||
|---|---|---|
 |  | |
| Chapter 3. Deriving Your Own Module from Module | ||
|---|---|---|
| | | |
Table of Contents
ModuleTypedCalculateOutputImageHandlerChapter Objectives
By reading this chapter you will learn how to derive your own ML
module from the class Module. You will receive
detailed information on the following methods:
Constructor,
Destructor,
activateAttachment,
handleNotification,
calculateOutputImageProperties,
calculateInputSubImageBox,
using TypedCalculateOutputImageHandler,
calculateOutputSubImage,
handleInput,
getTile,
getUpdatedInputImage.
Also, you will learn how to use and configure additional functionality, such as:
checking for interruptions,
multi-threading,
bypassing page data, and
activating the support of registered voxel types.
With MeVisLab version 2.2, a new concept to separate module functionality from image processing functionality has been introduced in the form of using a TypedCalculateOutputImageHandler. Read Section 3.1.5, “Using TypedCalculateOutputImageHandler” to learn more.
The chapter ends with a discussion of typical traps and pitfalls you
may encounter when you implement classes derived from
Module. See Section 3.1.18, “Traps and Pitfalls in Classes Derived from Module ”.
See Section A.1, “Creating an ML Project by Using MeVisLab”. for a quick start with module development.
![[Important]](images/important.png) | Important |
|---|---|
The ML module wizard in MeVisLab supports many of the steps discussed in the following sections. Use the wizard in order to avoid spending too much time on writing everything on your own! |
The following sections will explain how to implement your own image processing algorithm.
When you begin to implement your own ML image processing module, you usually just need the following include file:
#include "mlModuleIncludes.h"
All ML specific C++ code should be written within the namespace ML - thus no prefixes are needed before constants and classes, and collisions with other library symbols are minimized:
ML_START_NAMESPACE // here the ML specific code is added ML_END_NAMESPACEAn image processing module is derived from the class
ml::Module
. Since modules are usually
compiled in their own DLL (Windows:
"dynamic linked library", Linux:
"shared library", Mac OS: "dynamic shared libraries"), it may be necessary to export this
class on the DLL interface. Therefore, a macro
MLEXAMPLEOPSEXPORT is used to specify the export
of a class in the system header file of the DLL. See Section A.3, “Exporting Library Symbols”ML_START_NAMESPACE
class MLEXAMPLEOPSEXPORT AddExample : public Module
{
// class interface and/or code
}; // end of class AddExample
ML_END_NAMESPACE![[Note]](images/note.png) | Note |
|---|---|
Although exporting classes is only necessary on Windows platforms, it should be added while developing on other platforms as well in order to ensure platform-independence. |
Since a new ML module is usually compiled as a new library that
an application can load at runtime, you must make your module
accessible to a module database. The ML implements such a database as
a Runtime Type System (see also Section 2.2.4, “The Runtime Type System”). Thus implementing your own module
just requires a small interface to enter the module as a new type in
that runtime type system. Hence, it can give its name and its type on
request as well as create an instance of itself on demand. The
following macro (from file
mlRuntimeSubClass.h
)
declares the necessary class interface:
ML_START_NAMESPACE
class MLEXAMPLEOPSEXPORT AddExample : public Module
{
// class interface and/or code ...
// Implement runtime type interface of module. Add it at
// end of class declaration since it changes member access
// control to 'private'.
ML_MODULE_CLASS_HEADER(AddExample)
}; // end of class AddExample
ML_END_NAMESPACE | Important |
|---|---|
To make this class available to the runtime type system it is
necessary to call its static |
| Important |
|---|---|
Be sure that the class name is written correctly, since not all compilers are able to check for wrong names in that macro. |
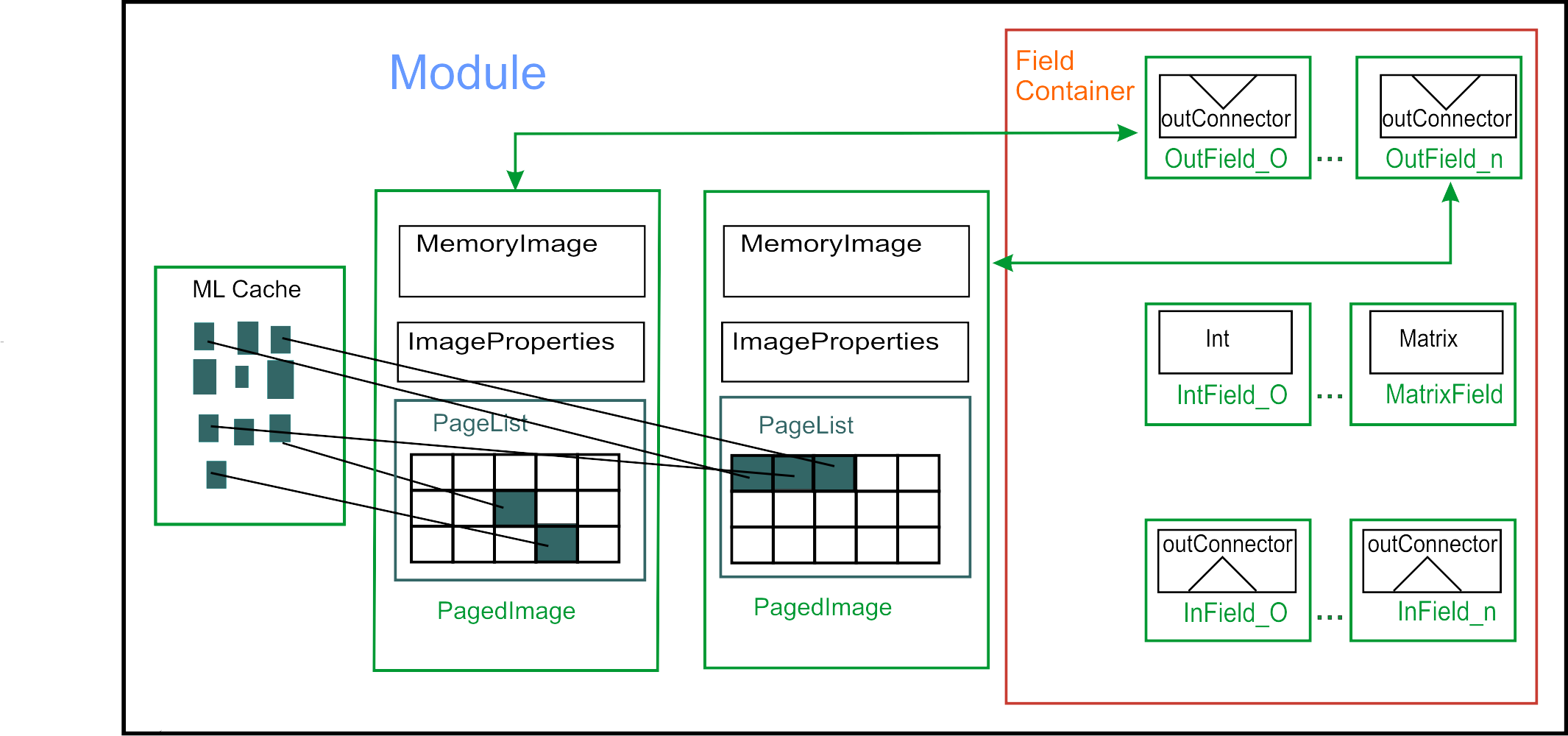
A simple overview of a Module:
The Module is derived from
FieldContainer that holds the module's
parameters:
The constructor is a crucial part of an ML module because it
generates the parameter interface (including inputs and outputs) and also initializes it,
enables/disables multithreading support,
specifies whether your module performs in-place calculations or bypasses image data,
can specify how changes to the parameter interface (including inputs) notify output images.
The implementation of the constructor must always include a base
class constructor call of the class Module, and
the number of image inputs and output a module is passed as arguments
(two inputs and one output in the example):
ML_START_NAMESPACE
AddExample::AddExample(): Module(2,1)
{
// ...
}
ML_END_NAMESPACESee also class FieldContainer (Section 2.1.3, “
FieldContainer
”) as well as classes
InConnectorField and
OutConnectorField (Section 2.1.2, “
Field
”)
for other ways of adding or removing inputs to/from your
modules.
Now a set of parameters can be added to specify the module
interface. Note that all fields are added to the module (see
also class FieldContainer).
Be aware that field names should only use alphanumeric characters and may not include spaces or special characters. The example code fragment adds a float and a Boolean parameter to the module interface and initializes them:
_addConstFld = addFloat("Constant");
_addConstFld ->setFloatValue(0);
_deleteVoxelFld= addToggle("DeleteVoxel");
_deleteVoxelFld->setIntValue(false);Programmers who favor short code can also write the following:
(_addConstFld = addFloat("Constant") )->setFloatValue(0);
(_deleteVoxelFld= addToggle("DelVoxel"))->setIntValue(false);Note that the members _addConstFld and
_deleteVoxelFld are pointers to the field types
that are created, and must be declared in the header file like
this:
private: // or protected FloatField *_addConstFld; ToggleField *_deleteVoxelFld;
Access functions can be implemented to make fields and module parameters directly accessible to an application without permitting field pointer changes. These functions are especially useful when further classes are to be derived from your class without the risk of derived classes doing modifications to invalid field pointers:
public:
inline FloatField &getAddConstFld() const { return *_addConstFld; }
inline ToggleField &getDeleteVoxelFld() const { return *_deleteVoxelFld; }If you want parameter changes to also invalidate the image output of the module and to notify connected modules of the changed/invalidated image, you can simply connect your field(s) to the changed output image:
_addConstFld ->attachField(getOutputImageField(0)); _deleteVoxelFld->attachField(getOutputImageField(0));
| Important |
|---|---|
If not disabled, field value changes notify all observers of
the field. Therefore the |
The following two methods (they may be nested) can be used to
avoid the handleNotification() being called when
field values are set:
handleNotificationOff(); // Change field values here without calling handleNotification(). handleNotificationOn();
| Note |
|---|---|
Input and output images are also ML module parameters and
therefore they are represented by fields
Since input and output fields can be added via the
superclass constructor, the methods |
Usually, input image changes need to invalidate the output and to notify the connected modules; if so, the output field(s) just have to be attached to the input field(s). This is possible because fields handle input images like other module parameters:
getInputImageField(0)->attachField(getOutputImageField(0)); getInputImageField(1)->attachField(getOutputImageField(0));
Some additional features of the Module
class allow the configuration of further image processing
behavior:
In-place image processing. See Section 3.1.11.1, “Inplace Image Processing”.
Bypassing image data. See Section 3.1.11.2, “Bypassing Image Data”.
Processing image data in parallel. See Section 3.1.11.3, “Multithreading: Processing Image Data in Parallel”.
Processing images of registered voxel types. See Section 3.1.11.4, “Processing Images of Registered Voxel Types”.
See Section 3.1.11, “Configuring Image Processing Behavior of the Module” for further details.
In common ML modules, the algorithm's parameters are implemented
as fields. Therefore, module persistence does normally not have to be
implemented, since the application usually should scan the field
interface of all ML modules as well as save and reload their states
from/to a file (see also Section 2.1.2, “
Field
” and Section 2.1.3, “
FieldContainer
”).
When an application reloads or clones ML modules, a specific problem needs particular attention. Within the given situation, the application and its connections usually re-create the network modules, and field values are restored. This causes some network modules to start calculation, because fields are updated by the loading process, which would not only result in long startup times but also in calculations being performed on partially invalid module data.
The solution to this problem is to disable field notifications
while loading ( handleNotification() and other
field observers are not called) and to notify all modules with a
"load-finish" signal when loading has been completed. So the modules
can update their internal states to the new field values in one step.
Many modules do not need to handle this signal, but some do. To
implement this update functionality, the method
activateAttachments()that stands for this "load
finished" signal can be overloaded:
virtual void activateAttachments()
{
// Implement your update stuff here ...
// Do not forget to call the super class functionality, it enables field
// notifications for your module again.
// SUPER_CLASS is the class you derive from (usually Module).
SUPER_CLASS::activateAttachments();
}As a general rule, you need to overload this method when your
class includes non-field members that require updates on field
changes. Update these members in
activateAttachments, because there you have the
new field setting after e.g., module reloads.
| Note |
|---|---|
The order of execution on loading a module is as follows:
|
Sometimes it is necessary to react on changes to the fields that
represent a module's interface. This can easily be done by overloading
the method handleNotification() which is called
when any field (value) is changed.
void AddExample::handleNotification(Field *field)
{
if (field == _addConstFld) {
/* The value of _addConstFld has changed. */
}
if (field == getInputImageField(0)) {
/* First input is (dis)connected, updated, invalidated... */
}
if (field == getInputImageField(1)) {
/* Second input is (dis)connected, updated, invalidated... */
}
} | Note |
|---|---|
The
|
![[Tip]](images/tip.png) | Tip |
|---|---|
The statement if (field==_addConstFld) { getOutputImageField()->touch(); }in _addConstFld->attachField(getOutputImageField()); in the constructor. |
Since MeVisLab version 2.2, a new way to implement typed image processing in an ML module has been introduced which is the default setting of MeVisLab's module wizard. It uses a separate class for the actual image processing which is derived from TypedCalculateOutputImageHandler.
Using a TypedCalculateOutputImageHandler has the following advantages:
It supports complex configurations of output/input type combinations (compared to the CALC_* macros).
It facilitates implementation of thread-safe image processing, since the processing is no longer done in the module itself.
It allows to have different output image handlers for different output images or even for different module states.
For further information, please read ml::TypedCalculateOutputImageHandler, ml::CalculateOutputImageHandler, and ml::Module::createCalculateOutputImageHandler.
The virtual method calculateOutputImageProperties(int outIndex, PagedImage* outImage) must be overloaded to change the properties of
the output images, as well as to change the properties of the input subimages
which are passed to calculateOutputSubImage().
For a certain output index, the method sets properties of the
output image (depending on the properties of the input images). Hence,
for each property of the output image outImage, the corresponding properties of any input image
getInputImage(0), ... ,
getInputImage(getNumInputImages()-1) can be merged and set
as new properties.
To change the properties of an input subimage, you can use the following methods
of the PagedImage:
void setInputSubImageDataType(int inputIndex, MLDataType datatype)
void setInputSubImageIsReadOnly(int inputIndex, bool readOnly)
void setInputSubImageUseMemoryImage(int inputIndex, bool useMemImg)
void setInputSubImageScaleShift(int inputIndex, const ScaleShiftData& scaleShift)
An access method to the input images is available with
getInputImage(int index).
| Note |
|---|---|
Do not use |
| Note |
|---|---|
In case of |
Input images and their properties within the
calculateOutputImageProperties() and
calculate*() methods are always valid and thus do not
have to be checked for validity.
Access methods to the image properties are defined in the
classes ImageProperties (Section 2.3.1, “
ImageProperties
”), MedicalImageProperties (Section 2.3.2, “
MedicalImageProperties
”) and
PagedImage (Section 2.3.4, “
PagedImage
”):
getImageExtent() and
setImageExtent(),
getBoxFromImageExtent(),
getPageExtent() and
setPageExtent(),
getDataType() and
setDataType(),
getMinVoxelValue() and
setMinVoxelValue(),
getMaxVoxelValue() and
setMaxVoxelValue(),
and many more.
If calculateOutputImageProperties() is not implemented,
the properties of getInputImage(0) are copied to the
output image(s).
The following example shows how to set some of the most important properties of an output image.
void ExampleModule::calculateOutputImageProperties(int outIndex, PagedImage* outImage)
{
// Set image extent
outImage->setImageExtent ( ImageVector(100,100,30,3,1,1) );
// Set page extent
outImage->setPageExtent( ImageVector(128,128,1,1,1,1) );
// Set estimated min voxel value
outImage->setMinVoxelValue( 0 );
// Set estimated max voxel value
outImage->setMaxVoxelValue( 255 );
// Set desired data type
outImage->setDataType(MLuint8Type);
} | Note |
|---|---|
Setting minimum and maximum voxel values can sometimes be a difficult task because page-based algorithms usually do not process the entire image and explicit testing of all voxel values is impossible. Therefore the typical approach to solve this problem is to set minimum and maximum voxel values in such a way that they include all voxel values that could occur. The minimum/maximum range can be set to be larger than the real voxel values in order to make things easier even when the minimum and maximum values become very large. These values are considered to be hints and no reliable values. However, the maximum value must always be equal to or greater than the minimum value. |
Changing properties of output images is only legal inside
the calculateOutputImageProperties() method.
Page extends must be left unchanged unless it is really necessary to avoid performance drawbacks. They must not set to the image's extend, since pages are usually inherited by subsequent modules, and setting a too large page extend will degenerate the underlying page concept.
The following code fragment must be used to
invalidate/validate the output image at index
outIdx:
// Invalidate the output image. outImage->setInvalid(); // Validate the output image. outImage->setValid();This is only to be used in
calculateOutputImageProperties()Before the algorithm can calculate the contents of an output
page, the required data portion / block from each input must be
specified in calculateInputSubImageBox(). The algorithm
must return that subimage region of the image at input
inIndex that is needed to calculate the
subimage region outSubImgBox of the output at
index outIndex:
virtual SubImageBox calculateInputSubImageBox(int inIndex,
const SubImageBox& outSubImgBox,
int outIndex)
{
// Do the same for all inputs and outputs:
// Get corners of output subimage.
const ImageVector v1 = outSubImgBox.v1;
const ImageVector v2 = outSubImgBox.v2;
// Request a box from input image which is shifted by 10 voxels to the left
// and 5 voxels to the front.
return SubImageBox(ImageVector(v1.x-10, v1.y-5, v1.z, v1.c, v1.t, v1.u),
ImageVector(v2.x-10, v2.y-5, v2.z, v2.c, v2.t, v2.u));
}The code is shorter when vector arithmetics are used:
virtual SubImageBox calculateInputSubImageBox(int inIndex,
const SubImageBox& outSubImgBox,
int outIndex)
{
// Request a box from input image which is shifted by 10 voxels to the
// left and 5 voxels to the front.
return SubImageBox(outSubImgBox.v1+ImageVector(-10, -5, 0,0,0,0),
outSubImgBox.v2+ImageVector(-10, -5, 0,0,0,0));
}If calculateInputSubImageBox is not implemented, the
default implementation returns the unchanged
outSubImgBox, i.e., if a certain region of the
output image is calculated, the same region is requested from the
input image.
| Note |
|---|---|
Requesting areas outside the input image is explicitly legal because this is often useful when input regions need to be bigger than output regions, e.g., for kernel-based image processing (Section 4.2.4, “Kernel-Based Concept”). However, image data requested from outside an image region will be undefined. |
As with MeVisLab version 2.1, this method has been removed.
The properties of the input subimages (typically changes to the data type of in the input
data before processing them) need to be set now in the method calculateOutputImageProperties(). This way,
the properties of the input subimages are set only once for each output image and not for each input
subimage request. Thus, the new way is faster and less error prone.
The ML calls this method to request the calculation of real image data or, to be more precise, to request the calculation of one output page.
In outSubImg, a pointer to a page of
output image outIndex is passed. The contents
of that page need to be calculated by the algorithm.
In inSubImgs, the pointers to the input
subimages are passed. These subimages contain the source data and
exactly the same image regions you requested in
calculateInputSubImageBox() for the output of index
outIndex. Note that the number of input
subimages depends on the number of module inputs; this number can be 0
if there are no module inputs (e.g., a ConstImg
or a Load module).
virtual void calculateOutputSubImage(SubImage *outSubImg, int outIndex, SubImage *inSubImgs){ ... }The data types of the input and output data can be any of the types supported by the ML, i.e., 8,16,32 or 64 bit integers, float, double or any of the registered data types. Implementing the algorithm to support all these data types is generally difficult, especially because it is not known whether future ML versions will contain other data types.
The solution to this problem is to implement a template function
that is automatically compiled for all data types. This, however,
requires the correctly typed template function to be called from
calculateOutputSubImage(). This should not be implemented
by the module developer because additional data types and
optimizations could change that process.
A set of predefined macros is available, e.g., the following can be used if there is one module input and the template function must be implemented in the C++ file.
ML_CALCULATEOUTPUTSUBIMAGE_NUM_INPUTS_1_SCALAR_TYPES_CPP(ExampleModule);
The correct macro is built from
the string ML_CALCULATE_OUTPUTSUBIMAGE,
the number of image inputs right behind this, coded as the string _NUM_INPUTS_*,
where * is one of 0, 1, 2,
3, 4, 5, 10 or N,
the string _SCALAR_TYPES or _DEFAULT_TYPES if the data types of input
and output subimages are the same and the module shall either only support scalar types or the default voxel type set, or
the string _DIFFERENT_SCALAR_INOUT_DATATYPES or _DIFFERENT_DEFAULT_INOUT_DATATYPES if different data types of input
and output subimages shall be allowed (requires using PagedImage::setDataType() and
PagedImage::setInputSubImageDataType() in the calculateOutputImageProperties() method).
Again this either only supports only scalar types or the default voxel type set. Note that all the subimages for each input image
still must have the same data type, only the types
between input and output subimages can differ,
alternatively you can have the string _WITH_CUSTOM_SWITCH (or _DIFFERENT_INOUT_DATATYPES_WITH_CUSTOM_SWITCH) if a subset of certain data types
shall be allowed only as input data types. There are a number of predefined macros for the switches
available, such as ML_IMPLEMENT_FLOAT_CASE for all floating point data types or
ML_IMPLEMENT_COMPLEX_CASES for complex data types, and the user can implement
new data type switches as well.
The whole macro must end with the string _CPP if the C++ file implementation
is used. If the header file implementation is used, no special ending string needs to be
provided.
As arguments for the macro, the class name of the module needs to be provided and if the macro should support a subset of custom data types, the macro that implements the switch for those data types needs to be provided as well.
| Note |
|---|---|
|
It is also possible to specify a subset of data types (e.g., only
integer, only float data, only standard data types) which will not be
discussed here. See Section 7.5.3, “Reducing Generated Code and Compile Times” and the file
mlModuleMacros.h
for more information.
| Important |
|---|---|
If not specified otherwise, the input subimages have always the same data type as the output subimages. However, the data type for the input subimages can the changed for each input image. To change the data type for a certain input image (and therefor
for each of its subimages), you need to implement this in the method
|
The template function with the algorithm can be implemented as follows:
template <typename DATATYPE>
void ExampleModule::calculateOutputSubImage(TSubImage<DATATYPE> *outSubImg,
int outIndex,
TSubImage<DATATYPE> *inSubImg0,
TSubImage<DATATYPE> *inSubImg1)
{
//...
}In this template function, the algorithm calculates the output
page outSubImg from the input page(s)
inImg1 and inImg2. This
method is instantiated for each data type. The method
calculateOutputSubImage calls this function by searching
the correct data type and by calling the correctly typed template
version. It is automatically implemented by the corresponding
ML_CALCULATE_OUTPUTSUBIMAGE macro.
The number of typed input subimages depends on the used macro, e.g., for zero inputs
template <typename DATATYPE>
void ExampleModule::calculateOutputSubImage(TSubImage<DATATYPE> *outSubImg, int outIndex)
{
//...
}for four inputs
template <typename DATATYPE>
void ExampleModule::calculateOutputSubImage(TSubImage<DATATYPE> *outSubImg,
int outIndex,
TSubImage<DATATYPE> *inSubImg0,
TSubImage<DATATYPE> *inSubImg1,
TSubImage<DATATYPE> *inSubImg2,
TSubImage<DATATYPE> *inSubImg3)
{
//...
}and for a dynamic number of inputs
template <typename DATATYPE>
void ExampleModule::calculateOutputSubImage(TSubImage<DATATYPE> *outSubImg,
int outIndex,
TSubImage<DATATYPE> **inSubImgs)
{
//...
}For two inputs and different input and output image data types:
template <typename ODTYPE, typename IDTYPE>
void ExampleModule::calculateOutputSubImage(TSubImage<ODTYPE> *outSubImg,
int outIndex,
TSubImage<IDTYPE> *inSubImg0,
TSubImage<IDTYPE> *inSubImg1)
{
//...
}This copies voxel by voxel from the input subimage to the
available output subimage, e.g., with the macro
ML_CALCULATEOUTPUTSUBIMAGE_NUM_INPUTS_1_SCALAR_TYPES_CPP(SubImgExampleModule):
template <typename DATATYPE>
void ExampleModule::calculateOutputSubImage(TSubImage<DATATYPE> *outSubImg,
int /*outIndex*/,
TSubImage<DATATYPE> *inSubImg0)
{
// Copy overlapping data from inSubImg0 to outSubImg.
outSubImg->copySubImage(*inSubImg0);
}Note that the classes TSubImage and its
base class SubImage provide a number of other
typed and untyped copy, fill and access methods for subimages and
their data.
This implements a voxel-wise copy from the input subimage to the output image, keeping track of the coordinate of the copied voxel:
template <typename DATATYPE>
void ExampleModule::calculateOutputSubImage(TSubImage<DATATYPE> *outSubImg,
int /*outIndex*/,
TSubImage<DATATYPE> *inSubImg0)
{
// Determine overlapping and valid regions of page and image, because the
// page could reach outside valid image region.
const SubImageBox box = inSubImg0->getValidRegion();
// Traverse all voxels in box
ImageVector p = box.v1;
for (p.u = box.v1.u; p.u <= box.v2.u; ++p.u) {
for (p.t = box.v1.t; p.t <= box.v2.t; ++p.t) {
for (p.c = box.v1.c; p.c <= box.v2.c; ++p.c) {
for (p.z = box.v1.z; p.z <= box.v2.z; ++p.z) {
for (p.y = box.v1.y; p.y <= box.v2.y; ++p.y) {
// Set x coordinate of first voxel in row.
p.x = box.v1.x;
// Get pointer to input voxel at position p.
const DATATYPE * inPtr0 = inSubImg0->getImagePointer(p);
DATATYPE * outPtr = outSubImg->getImagePointer(p);
// Implement inner loop without function calls and use
// pointer iterations for a better performance.
for (; p.x <= box.v2.x; ++p.x) {
*outPtr = *inPtr0; // Copy input voxel to output voxel.
++outPtr; // Move both voxel pointers forward.
++inPtr0;
}
}
}
}
}
}
}The following code fragment shows the implementation for one input and one output of different types for input and output subimages. The macro
ML_CALCULATEOUTPUTSUBIMAGE_NUM_INPUTS_1_DIFFERENT_SCALAR_INOUT_DATATYPES_CPP(ExampleModule)is used for that in addition of change of the data type in the
calculateOutputImageProperties method://! Select either MLint64 or MLdouble as output type.
void ExampleModule::calculateOutputImageProperties(int outIndex, PagedImage* outImage)
{
if (MLIsIntType(outImage->getDataType()))
{
// Use int64 instead of any other int type.
outImage->setDataType(MLint64Type);
}
else
{
// Use double for all other types.
outImage->setDataType(MLdoubleType);
}
// Set the data type of the input image to the input subimages
// instead of the data type of the output image (which is the default).
outImage->setInputSubImageDataType(0, getInputImage(0)->getDataType());
}
//! Implement the calls of the right template calculateOutputSubImage code
//! for the current image data type for all data type combinations.
ML_CALCULATEOUTPUTSUBIMAGE_NUM_INPUTS_1_DIFFERENT_SCALAR_INOUT_DATATYPES_CPP(ExampleModule);
template <typename ODTYPE, typename IDTYPE>
void ExampleModule::calculateOutputSubImage(TSubImage<ODTYPE> *outSubImg,
int /*outIndex*/,
TSubImage<IDTYPE> *inSubImg0)
{
// Determine overlapping and valid regions of page and image, because the
// page could reach outside the valid image region.
const SubImageBox box = inSubImg0->getValidRegion();
// Traverse all voxels in the box
ImageVector p = box.v1;
for (p.u = box.v1.u; p.u <= box.v2.u; ++p.u) {
for (p.t = box.v1.t; p.t <= box.v2.t; ++p.t) {
for (p.c = box.v1.c; p.c <= box.v2.c; ++p.c) {
for (p.z = box.v1.z; p.z <= box.v2.z; ++p.z) {
for (p.y = box.v1.y; p.y <= box.v2.y; ++p.y) {
// Set x coordinate of first voxel in row and
// get pointer to input voxel at position p.
p.x = box.v1.x;
const IDTYPE * inPtr0 = inSubImg0->getImagePointer(p);
ODTYPE * outPtr = outSubImg->getImagePointer(p);
// Implement inner loop without function calls and use
// pointer iterations for a better performance. Use a
// cast to convert voxel types warn free.
for (; p.x <= box.v2.x; ++p.x)
{
// Copy input voxel to output voxel.
*outPtr = static_cast<ODTYPE>(*inPtr0);
// Move both voxel pointers forward.
++outPtr;
++inPtr0;
}
}
}
}
}
}
}An implementation with fixed input/output types and without
templates or macros is also possible if the programmer takes care of
correct TSubImage for the fixed types:
//! Always select MLint32 as output type.
void ExampleModule::calculateOutputImageProperties(int outIndex, PagedImage* outImage)
{
outImage->setDataType(MLint32Type);
// Always select MLdouble as voxel type for input subimages.
outImage->setInputSubImageDataType(0, MLdoubleType);
}
//! Implement explicitly the copy from the double typed input
//! buffers to the int32 typed output subimage.
void ExampleModule::calculateOutputSubImage(SubImage *outSubImg,
int /*outIndex*/,
SubImage *inSubImgs)
{
// You can use either the untyped copySubImage() method:
outSubImg->copySubImage(inSubImgs[0]);
// ... or build typed subimages from the untyped ones and implement
// loops as in previous examples on typed oSubImg and iSubImg.
TSubImage<MLint32> oSubImg(*outSubImg);
TSubImage<MLdouble> iSubImg(inSubImgs[0]);
// ... implement voxel loop as in previous examples here
}See Section 3.1.17, “Processing Input Images Sequentially” and
Section 7.2.3, “Examples with Registered Voxel Types”, and ML example
codes in MeVisLab for further and advanced examples
of calculateOutputSubImage() implementations.
| Important |
|---|---|
Subimages contain a set of image properties that can be
useful for programming. However, it would require a significant
effort to calculate the |
| Tip |
|---|---|
Have a close look at the class
Many problems (and solutions) like global input image access in pages etc. are discussed there as well. |
By default, a module's
Module::calculate* methods are not called when any of its input images
are disconnected or connected to an
invalid image. This, however, is desired in some cases, e.g.,
to support optional input images or when implementing a Switch module
that has multiple inputs and only a few of them are connected and valid, while only one of the
images shall be passed to the output image.
To support disconnected or invalid input images, one has to overload the following method:
virtual INPUT_HANDLE handleInput(int inIndex, INPUT_STATE state) const;
Whenever an input is disconnected or invalid while it is being
accessed, the ML internally calls handleInput()
with the current input state and requests how to handle this situation.
ask for a task with that input. There
are some cases to be handled when input at index
inIndex is accessed via a
Module method:
The input is connected and valid.
Normal image processing takes place, and the
handleInput() method is not called.
The input is disconnected or connected but invalid after trying to update its properties.
This case is notified by
the parameter state with value
DISCONNECTED or CONNECTED_BUT_INVALID.
There are two possibilities:
handleInput() returns INVALIDATE and no image processing can take place (which is the default).
handleInput() explicitly allows an invalid input image by returning ALLOW_INVALID_INPUT.
Image processing will continue and getInputImage(inIndex) will return NULL for that index.
The ML Host will not request data from this image and subimages passed to calculateOutputSubImage
will be empty for that input image.
| Important |
|---|---|
|
| Note |
|---|---|
Disconnected and connected but invalid inputs can be handled
differently by using the passed |
When looking at a module's input, it may have one of the following states (of enum type INPUT_STATE):
DISCONNECTED - no image is connected.
CONNECTED_AND_VALID - an image is connected and it is valid.
CONNECTED_BUT_INVALID - an image is connected but invalid, even after trying to update its properties.
CONNECTED_BUT_NEEDS_UPDATE - an image is connected but its properties are out of date and need updating. After the update, it may become valid or invalid.
INPUT_STATE *getInputState(int inIndex)If the input image should be updated as well, you may use:
INPUT_STATE *getUpdatedInputState(int inIndex)which will never return
CONNECTED_BUT_NEEDS_UPDATE, since it will update the image properties if an update is required.
The Module class provides a method to handle the getting of updated input images.
PagedImage *getUpdatedInputImage(int i, bool getReal=false)
This is a convenience method for accessing the input image at
index i. If there is any possibility to get a
valid and accessible input image, this method will return a pointer
to its PagedImage, otherwise
NULL is returned.
The Module class offers some further methods to
control image processing behavior. The following sections describe
these features.
In some image processing algorithms the input and output pages
have the same extent and data type. Hence, the algorithms might only
need one buffer which is input and result (i.e.
output) at the same time instead of having different buffers for the
input and the output pages. Typical algorithms are e.g lookup,
thresholding or arithmetic operations. You can instruct the ML to
use only one buffer by calling the setOutputImageInplace(int outIndex=0, int inIndex=0) method, because that avoids
unnecessary buffer allocating and memory copying. Furthermore, the
CPU does not need to switch between different memory areas which
improves prefetching. The following methods are available to enable
inplace operation for the calculateOutputSubImage()
method:
//! Set optimization flag: If calculating a page in calculateOutputSubImage() //! the output image page of output outIndex shall use the same //! memory as the input page of input inIndex. So less allocations occur //! and the read and written buffer are identical. Usually only useful for //! pixel operations or algorithms which do not modify the image data. //! Setting inIndex = -1 disables inplace optimization for the given outputIndex. protected: void setOutputImageInplace(MLint outIndex=0, MLint inIndex=0); //! Clear optimization flag: output page of output and input tile shall //! use different memory buffers in calculateOutputSubImage(). //! This is an equivalent to setOutputImageInplace(outIndex, -1). protected: void unsetOutputImageInplace(MLint outIndex=0); //! Return optimization flag: Return index of input image whose input tile //! is used also as output page for output outIndex in calculateOutputSubImage() //! (instead of allocating its own memory). If inplace calculation is off //! then -1 is returned. public: MLint getOutputImageInplace(MLint outIndex=0) const;
| Note |
|---|---|
|
Some modules only change image properties, but do not modify
actual image data. Examples of such algorithms are the
Switch or the Bypass
modules which only propagate data. Nor does the
ImagePropertyConvert modify the image data
when using its default behavior.
In this case, it is useful to avoid pages being processed by the module or being cached at the module's output. This reduces the amount of memory copies and the number of pages stored in the ML cache, i.e., the memory load of the application using these modules is reduced.
This feature can be configured by the following two methods
(similar to the setOutputImageInplace() method)
:
//! Sets the input image whose pages can also be used instead of output pages //! to avoid recalculations. Setting an inIndex of -1 disables bypassing //! (which is the default). //! Bypassing require image (data) content, image extent, page extent and //! voxel data type ro remain unchanged, or errors will occur. protected: void setBypass(MLint outIndex=0, MLint inIndex=0); //! Returns the currently bypass index or -1 if bypassing is disabled (default). //! Bypassing require image (data) content, image extent, page extent and //! voxel data type to remain unchanged, or errors will occur. public: MLint getBypass(MLint outIndex=0) const;
| Note |
|---|---|
|
The ML supports multithreading, i.e., it can perform image
processing tasks in parallel if supported by the module's algorithm.
Currently, only the calculateOutputSubImage() method of
Module (or its overloaded method) is called
in parallel. The following Module method and
enumerator values are used to activate parallel computation:
//! Pass any THREAD_SUPPORT mode to decide whether and what type of multithreading
//! is supported by this module. See THREAD_SUPPORT for possible modes.
void setThreadSupport(THREAD_SUPPORT supportMode);
//! Enumerator deciding whether and which type of multithreading
//! is supported by this module.
enum THREAD_SUPPORT {
//! The module is not thread safe at all.
NO_THREAD_SUPPORT,
//! calculateOutputSubImage is thread-safe for scalar voxel types.
ML_CALCULATE_OUTPUTSUBIMAGE_ON_STD_TYPES,
//! calculateOutputSubImage is thread-safe for all voxel types.
ML_CALCULATE_OUTPUTSUBIMAGE_ON_ALL_TYPES,
};
| Note |
|---|---|
|
| Important |
|---|---|
Since multithreading errors are often difficult to debug, it
must be made sure that algorithms are really thread-safe before
the multithreaded execution of
|
To ensure thread-safe operations, it must be possible to
execute many parallel versions of the algorithm without modifying
shared data. Local variables, for example, are normally
thread-safe, because they are stored in the local stack of the
concerning thread. If parallel access to shared objects is required,
special synchronization mechanisms must be used. The ML makes use
of the boost::thread libary and provides simple
wrappers in the header files
mlThread.h
,
mlMutex.h
,
and
mlBarrier.h
as well as Section 3.1.11.3.1, “How to Implement Thread-Safe Code Fragments” for more
information.
An algorithm (or to be more precise:
calculateOutputSubImage()) is not thread-safe
when it is not reentrant.
when non-local variables are written without synchronization like mutex locking (see Section 3.1.11.3.1, “How to Implement Thread-Safe Code Fragments”).
when any stream, debug or other console output is used; so
do not use methods like std::cout,
std::cerr or printf.
It is safe to use mlDebug,
mlWarning, mlError and mlInfo.
when fields are accessed.
when getTile() methods are called
from within calculateOutputSubImage(). This is also
true for
VirtualVolume classes, because they use
getTile internally.
In most (but not all!) cases, it is legal to modify and use
the following objects in the implementation of
calculateOutputSubImage:
Non-static local objects of the function if they are marked as re-entrant classes
(e.g.,
ImageVector, SubImageBox
, Vector2, ...,
quaternions, etc.),
functions and methods if they do not modify data like constant get functions, read access to members, etc.,
the input and output subimages passed to
calculateOutputSubImage because they are
thread-local objects (with the exception of input buffers using
MemoryImage),
all methods of input and output
SubImage and TSubImage
objects passed as calculateOutputSubImage
parameters.
The following two sections discuss strategies of how to implement thread-safe code.
In some cases, it might be useful to modify objects from
within the calculateOutputSubImage function although
it is called in parallel by the ML. This, for example, happens
when statistical values are summed up from all pages and composed
in members of the class. The most typical solution to this problem
is to protect a code fragment against parallel execution with a
so-called mutex implemented as a member of
your class. Include
mlMutex.h
for such code.
#include "mlMutex.h"
ML_START_NAMESPACE
class ML_EXAMPLE_PROJECT_EXPORT ExampleModule : public Module
{
// ...
private:
//! The mutual exclusion object to protect a code fragment.
Mutex _mutex;
// The member or object to be protected against parallel modification.
int _myMember;
// ...
};
template <typename DATATYPE>
void ExampleModule::calculateOutputSubImage(TSubImage<DATATYPE> *outSubImg,
int outIndex,
TSubImage<DATATYPE> *inSubImg)
{
double voxVal = 0;
// TODO: Here the loop calculates "voxVal"...
{
Lock(_mutex);
// This area is protected against parallel execution. The area between
// lock() and unlock() is entered only by one thread at once; another thread
// will not pass lock() until the current thread has passed unlock().
_myMember += voxVal;
}
// ...
}
ML_END_NAMESPACE | Note |
|---|---|
|
The ML supports processing of images with non-scalar and user-registered voxel types. See Chapter 7, Registered Voxel Data Types for detailed information on activation. In the default setup of an ML module, this feature is disabled and must be activated by the programmer when needed:
enum PERMITTED_TYPES {
//! Allows only scalar voxel types, the default.
ONLY_SCALAR_TYPES,
//! Enables all scalar voxel types and a default set
//! of extended voxel types like complex numbers and
//! some vector and matrix types.
ONLY_DEFAULT_TYPES,
//! Enables all voxel types registered for the ML.
ALL_REGISTERED_TYPES
};
//! Specifies which types this module supports. Default
//! is ONLY_SCALAR_TYPES.
void setVoxelDataTypeSupport(PERMITTED_TYPES permTypes); | Note |
|---|---|
|
| Important |
|---|---|
Using registered voxel types in multithreaded modules requires additional care by the programmer. See Section 3.1.11.3, “Multithreading: Processing Image Data in Parallel” for details. |
Sometimes it might be useful to explicitly request image data
from a module input. The Module provides some
functions to do so. In such functions, a data type and a subimage from
the input can be specified to get an explicit copy of that region in
memory. This is also permitted in
calculateOutputSubImage(), because a copy is needed for
extraordinary image requests (which, however, requires multithreading
for that module to be disabled). Note that the following functions are
also available in PagedImage objects that are
returned by the getUpdatedInputImage() and
getInputImage() methods, shown as second
versions.
The following functions are available:
static MLErrorCode Module::getTile(Module *op,
int outIndex,
SubImageBox loc,
MLDataType dataType,
void **data,
const ScaleShiftData &scaleShiftData =
ScaleShiftData());
or
MLErrorCode PagedImage::getTile(SubImageBox loc,
MLDataType dataType,
void **data,
const ScaleShiftData &scaleShiftData =
ScaleShiftData());This function requests a subimage region
loc from the image at output
of module
outIndex
. The data is stored
into memory with type op
dataType and scaled
with the settings specified in
scaleShiftData. data
is a void* pointer; and there are two cases
to distinguish. First, if the void*
pointer is NULL, the necessary memory for the
subimage data is allocated and the void* pointer is
set to the allocated memory address. Second, if the pointer is not
NULL, the memory address is used to store the
subimage data; the memory must be sufficiently large to avoid
buffer overrun errors.
If the memory is allocated by the
getTile function, the memory needs to be
released by MLFree()
(see freeTile() below).
static MLErrorCode Module::getTile(Module *op,
int outIndex,
SubImage *subImg,
const ScaleShiftData &scaleShiftData =
ScaleShiftData());
or
MLErrorCode PagedImage::getTile(SubImage &subImg,
const ScaleShiftData &scaleShiftData =
ScaleShiftData());Generally, this function operates in the same way as the
first version did. However, data type, data pointer and subimage
region are retrieved from subImg.
static MLErrorCode Module::getTile(Module *op,
int outIndex,
SubImageBox loc,
MLDataType dataType,
MLMemoryBlockHandle &memoryBlockHandle,
const ScaleShiftData &scaleShiftData);
or
MLErrorCode PagedImage::getTile(SubImageBox loc,
MLDataType dataType,
MLMemoryBlockHandle &memoryBlockHandle,
const ScaleShiftData &scaleShiftData);This function generally also works in the same way as the
first version. However, the data pointer is retrieved from
memoryBlockHandle and the allocated
subimage is inserted into the current cache tables.
Use the function freeTile() to release
the memory allocated by getTile() functions.
It is safe to pass NULL pointers to
freeTile():
static void Module::freeTile(void* data);
or
void PagedImage::freeTile(void* data); | Important |
|---|---|
Using one of the above functions requires the addressed
module outputs or images to be up to date. To test and/or to
update outputs,
|
Example 3.1. Explicitly Requesting Image Data (as double Voxels) from a Module Input:
if (getUpdatedInputImage(inputNum) != NULL) {
// Pass NULL pointer for automatic memory allocation when calling getTile().
void *data=NULL;
// Get unscaled double data from box with subImgCorner1 and subImgCorner2.
const MLErrorCode localErr = getTile(getInOp(inputNum), getInOpIndex(inputNum),
SubImageBox(subImgCorner1, subImgCorner2),
MLdoubleType,
&data,
ScaleShiftData(1,0));
// Test for general errors and for out of memory.
if (localErr != ML_RESULT_OK) {
if (ML_NO_MEMORY == localErr) {
mlError("TestOp::loadData", ML_NO_MEMORY) << "Out of Memory!";
} else{
mlError("TestOp::loadData", localErr) << "Could not get input image tile!";
}
} else {
// Everything okay, we can use the data.
}
// Free the allocated data and reset pointer.
freeTile(data);
data = NULL;
}Sometimes it is useful to request single voxel values from a
module input. This can easily be done by using the following
Module function:
Example 3.2. How to Get a Single Voxel Value from an Image as a String
static std::string getVoxelValueAsString(Module *op, int outIdx, const ImageVector &pos,
MLErrorCode *errCode=NULL,
const std::string &errResult="");The function returns the voxel value at position
pos of output outIdx of
the module op as a standard string. When an
error occurs, errResult is returned instead of
the voxel value. errCode can be passed as
NULL (the default). Otherwise, errors are
reported in *errCode or
ML_RESULT_OK is set. If the requested voxel
position is out of the image range, an empty string ( "") is returned
and *result is set to ML_RESULT_OK.
| Note |
|---|---|
This function is a convenience function for single voxel
access and uses |
In a well designed ML module class derived from
Module, there is normally no need to handle
errors in calculateOutputSubImage() or
calculateInputSubImageBox(), because invalid parameters
are usually already handled or corrected in
handleNotification() or the output image is
invalidated in calculateOutputImageProperties() with
outImage->setInvalid(). This is the usual
way to ensure that further calls of other
calc*()methods do not have to operate with
incorrect settings.
These error handling options, however, do not cover all
potential error sources. When a module reads data from a file in
calculateOutputSubImage(), for example, a file IO error
could occur. Since no calc*() method offers
return values and an invalidating of the output image is too late,
there is only the option to throw an exception. The following code
fragment demonstrates how this can be implemented in all
calc*() methods but
calculateOutputImageProperties():
template <typename T>
void ExampleModule::calculateOutputSubImage(TSubImage<T> *outSubImg, int outIndex)
{
MLErrorCode errCode = _loader->getTileFromFileIntoSubImg(*outSubImg);
if (ML_RESULT_OK != errCode) {
throw errCode; // Throw error to terminate loading process.
}
} | Note |
|---|---|
|
In some algorithms, it might be useful to check whether a stop button has been pressed to provide the option to terminate long calculations. The function
//! Checks if a notify button was pressed (outside of normal notification) //! It returns the notify field or NULL if nothing was pressed. Note that //! more than one field may have been notified; so use a loop until NULL is //! returned to be sure that all NotifyFields have been checked. Field *Module::getPressedNotifyField();
performs such a check on notify fields. A corresponding field can be created in the constructor:
NotifyField *_stopButtonFld; // Header
_stopButtonFld = addNotify("stop"); // ImplementationThe following function checks whether the button has been pressed during operation:
bool stopPressed()
{
Field* field = NULL;
do {
field = getPressedNotifyField();
if (field == _stopButtonFld) {
return true;
}
} while (field != NULL);
return false;
}An alternative way to check if processing should be terminated is to call
bool Module::shouldTerminate();This method returns true if any button has been pressed that was marked with
globalStop = true in the MDL definition (even if it
belongs to another modules), or if the stop button in the lower right
corner of the IDE main window was pressed. | Note |
|---|---|
|
Normally, a programmer does not need to not care about the
extent of pages, because import modules such as
ImageLoad normally set it up
appropriately.
However, some modules change the extent of images or even generate new images that require the calculation of new page extents. An appropriate extent of pages depends on many parameters, e.g., on the dimension of an image, its extent, whether it uses colors, the types of algorithms processing it, the number of processors or threads, the memory size or even whether it is processed on a 32 or 64 bit system. The following convenience function implements a heuristic to provide an appropriate page extent:
//! Adapt page extent. Arguments are:
//! - pageExt: Suggested page extent (e.g., of input image), overwritten
//! by new page extent
//! - imgType: Data type of output image
//! - newImgExt: Extent of output image
//! - oldImgExt: Extent of input image
//! - pageUnit: Page extent must be a multiple of this, or
/?! ImageVector(0) if do not care
//! - minPageExt: Minimum page extent, or ImageVector(0) if do not care
//! - maxPageExt: Maximum page extent, or ImageVector(0) if do not care
static void ModuleTools::adaptPageExtent(ImageVector &pageExt,
MLDataType imgType,
const ImageVector &newImgExt,
const ImageVector &oldImgExt,
const ImageVector &pageUnit = ImageVector(0),
const ImageVector &minPageExt = ImageVector(0),
const ImageVector &maxPageExt = ImageVector(0)); | Note |
|---|---|
The correct position to call the convenience function is
inside the method |
Certain algorithms are hard to implement with the image processing methods presented so far. These are algorithms that are applied to an image to only "extract" information instead of modifying the image data. Such algorithms need a special call due to the fact that the extraction of information is not triggered page-wise by any consuming module.
For this purpose, the following special
Module method can be called:
MLErrorCode processAllPages(int outIndex = -1)
This method processes all pages of an image and allows for an
easy implementation of page-based image processing algorithms on
entire images. Internally, all pages of the output image with index
outIndex are requested as from a connected (consuming)
module.
A common image processing is executed with the following deviations:
If outIndex is -1, a temporary
output image with the same negative index -1
is created and calculateOutputImageProperties() is called with
an outIndex of -1 and the temporary output image
as outImage. By checking for outIndex == -1,
it can be detected if the call was initiated by processAllPages()
and the properties of the temporary output image can be adjusted as desired.
By default, the temporary output image has the properties of the first input
image (at inputIndex == 0).
If outIndex is -1, as described
in Section 3.1.9, “Implementing calculateOutputSubImage()”, the output pages must
not be written since no data is
allocated for them to improve performance for pure input scanning
algorithms.
The output index outIndex is passed
to calculateOutputSubImage () and
calculateInputSubImageBox (), even if it is -1
(see Section 3.1.9, “Implementing calculateOutputSubImage()” and Section 3.1.7, “Implementing calculateInputSubImageBox()” ). By checking if the value is -1, you
know that the output must not be written and that the call
comes from processAllPages().
The return value is ML_RESULT_OK on a
successful operation, otherwise a code describing the error is
returned.
As in common page-based image processing, all pages of the input image(s) are requested from the input(s) in order to process the (possibly not existing) output page. Thus multiple inputs can be processed simultaneously with almost the same concept as it is done in common page processing. If only one input is to be scanned and if others are to be ignored, simply request empty page boxes for those (see Section 3.1.7, “Implementing calculateInputSubImageBox()”).
The following example demonstrates how to calculate the average of all voxels from input 0 whose corresponding voxels from input 1 are not zero. Input 2 will be ignored:
Example 3.3. Average Calculation of Masked Voxels in a 3-Input Module
// ********** HEADER FILE:
#include "mlModuleIncludes.h"
ML_START_NAMESPACE
class ExampleModule : public Module
{
protected:
ExampleModule();
virtual void handleNotification(Field *f);
virtual SubImageBox calculateInputSubImageBox(int inIndex,
SubImageBox &outBox,
int /*outIndex*/);
virtual void calculateOutputSubImage(SubImage *outSubImg,
int outIndex,
SubImage *inSubImgs);
template <typename DATATYPE>
void calculateOutputSubImage(TSubImage<DATATYPE> * /*outSubImg*/,
int outIndex,
TSubImage<DATATYPE> *inSubImg0,
TSubImage<DATATYPE> *inSubImg1,
TSubImage<DATATYPE> * /*inSubImg2*/);
private:
NotifyField *_processPagesFld;
long double _voxelSum;
long int _voxelNum;
ML_MODULE_CLASS_HEADER(ExampleModule);
};
ML_END_NAMESPACE// ********** SOURCE FILE:
ML_START_NAMESPACE
ML_MODULE_CLASS_SOURCE(ExampleModule, Module);
ExampleModule::ExampleModule(): Module(3,1)
{
_processPagesFld = addNotify("ProcessPages");
}void ExampleModule::handleNotification(Field *f)
{
if (f == _processPagesFld) {
_voxelSum = 0;
_voxelNum = 0;
processAllPages(-1);
if (_voxelNum != 0) {
mlDebug("Masked Average:" << _voxelSum/_voxelNum);
} else {
mlDebug("No masked voxels");
}
}
}SubImageBox ExampleModule::calculateInputSubImageBox(int inIndex,
SubImageBox &outBox,
int /*outIndex*/)
{
// Request page boxes from inputs 0 and 1 and get empty
// region from input 2.
if (inIndex == 2){
return SubImageBox();
} else {
return outBox;
}
}// Implement the calls of the right template code for the
// current image data type.
ML_CALCULATEOUTPUTSUBIMAGE_NUM_INPUTS_3_SCALAR_TYPES_CPP(ExampleModule);
template <typename DATATYPE>
void ExampleModule::calculateOutputSubImage(TSubImage<DATATYPE> * /*outSubImg*/,
int outIndex,
TSubImage<DATATYPE> *inSubImg0,
TSubImage<DATATYPE> *inSubImg1,
TSubImage<DATATYPE> * /*inSubImg2*/)
{
// Get valid page box clamped to valid image regions. Then
// scan all voxels in box.
SubImageBox box = inSubImg0->getValidRegion();
ImageVector p = box.v1;
for (p.u = box.v1.u; p.u <= box.v2.u; ++p.u) {
for (p.t = box.v1.t; p.t <= box.v2.t; ++p.t) {
for (p.c = box.v1.c; p.c <= box.v2.c; ++p.c) {
for (p.z = box.v1.z; p.z <= box.v2.z; ++p.z) {
for (p.y = box.v1.y; p.y <= box.v2.y; ++p.y) {
p.x = box.v1.x;
DATATYPE* i0P = inSubImg0->getImagePointer(p);
DATATYPE* i1P = inSubImg1->getImagePointer(p);
for (; p.x <= box.v2.x; ++p.x){
if (*i1P != 0) {
// Sum up masked voxels
++_voxelNum;
_voxelSum += *i0P;
}
// Move input pointers forward.
++i0P; ++i1P;
}
}
}
}
}
}
}
ML_END_NAMESPACEThis section discusses typical errors in programming image
processing filters derived from Module:
Typical errors are
to forget to implement
ML_MODULE_CLASS_SOURCE,
ML_MODULE_CLASS_HEADER or to call the
initClass() function (mostly in the Init file
of the dll/shared object). It registers the class in the runtime
type system of the ML. In MeVisLab, also a .def file with the
MLModule entry and the correct DLL tag must
exist.
This causes e.g., MeVisLab to not being able to detect or create the module on a network.
to forget to overload the virtual method
activateAttachments() in your module if
non-field members in the class depend on field settings.
This leads to incorrectly restored module networks, e.g., in MeVisLab. See Section 3.1.3, “Module Persistence and Overloading activateAttachments()” for details.
to forget to suppress calls of the method
handleNotification() while fields in the
constructor are added and initialized.
This causes calls of
handleNotification() with unexpected results
or crashes during module initialization. Use the methods
handleNotificationOff() and
handleNotificationOn() around the
initialization area of fields in the constructor.
to forget to connect input connector or other fields with the output connector fields if an automatic update of the output image is desired when these fields change.
This often leads to output images that are not or only partially up to date or that do not update correctly on parameter/field changes.
to change the number of inputs in the superclass call of
Module (e.g., MyClass(...) : Module(numInputs, numOutputs) ) and to forget to change the
ML_CALCULATE_OUTPUTSUBIMAGE macro and the parameters of the
calculateOutputSubImage()template.
This problem is not detected by some compilers and leads to
empty or missing implementations of
calculateOutputSubImage().
to enable the thread support without an explicit check
whether calculateOutputSubImage() is really
thread-safe.
See Section 3.1.11.3, “Multithreading: Processing Image Data in Parallel” for details.
to change the properties of output images outside the
calculateOutputImageProperties() method or even from
inside other calc* methods.
See Section 3.1.6, “Implementing calculateOutputImageProperties()” for details.
to forget to check the validity of the input images or
connectors when accessing inputs in
handleNotification().
Use getUpdatedInputImage() to check and get
the input image correctly. Note that the ML guarantees valid input
images in all
methods. This permits the access of these images directly with
calc*
getInputImage(idx)without further validity checks.
See Section 3.1.10.1, “Checking Module Inputs for Validity” and Section 3.1.10, “Handling Disconnected or Invalid Inputs by Overloading handleInput()” for more details.
to forget to clip the extent of the processed output page in
calculateOutputSubImage() against the extent of the
output image.
Since pages can reach outside the image, unused regions are processed and possibly read from the input buffers. Although it is not an error to fill regions of the output page that reach outside the image, it is useless and adversely affects performance. The problem can simply be solved by clipping the region of the processed output page against the output image region:
const SubImageBox boxToProcess = outSubImg->getValidRegion();
to forget that a SubImageBox has two
corners v1 and v2
which both are part of the
described region. Empty regions are denoted by any component in
v2 which is smaller than the corresponding
one in v1.
Hence, to process the region box
"<=" comparisons are needed in the loops
over all dimensions:
ImageVector p = box.v1; for (p.u = box.v1.u; p.u <= box.v2.u; p.u++) { for (p.t = box.v1.t; p.t <= box.v2.t; p.t++) { for (p.c = box.v1.c; p.c <= box.v2.c; p.c++) { for (p.z = box.v1.z; p.z <= box.v2.z; p.z++) { for (p.y = box.v1.y; p.y <= box.v2.y; p.y++) { for (p.x = box.v1.x; p.x <= box.v2.x; p.x++) { // . . . } } } } } }
to forget that the default behavior of a
Module class is to pass input data to
calculateOutputSubImage() which is of the type of the
output image, even if the
connected input image has another voxel type. Hence, the input
data might be cast implicitly. This typically simplifies module
programming and created code, because the type of input and output
voxels are identical and only one template argument is needed for
calculateOutputSubImage(). Note that the default
behavior of a Module class is for the
output image to inherit the data type of the input image which
minimizes data conversions and ensures that all modules process
the same data type by default.
See Section 3.1.6, “Implementing calculateOutputImageProperties()” for details if you need to have differently typed input and output buffers.
to forget that a dynamic number of input subimages
implemented with a ML_CALCULATE_OUTPUTSUBIMAGE_NUM_INPUTS_*N* macro
requires the implementation of the template function
calculateOutputSubImage with a T
at its end. Otherwise, internal ambiguities with other inherited
Module methods appear.
© 2026 MeVis Medical Solutions AG
| | | |
| 2.8. ML Data Types |  | Chapter 4. Image Processing Concepts |