DirectoryDownloader¶
Purpose¶
DirectoryDownloader downloads files from a web “directory”. The files to download are determined by parsing a given web page and stored in a Destination Directory. It is useful to download or mirror files from a web site.
Notes:
The HTTP(s) protocol does not support explicit folder or directory accesses which allowed an automatic access to the files shown on a page. The only way to download a web “directory” is to parse the downloaded web page displaying the “directory” for file links, for example by searching for introducing (see
Start Sub String) and finishing (seeEnd Sub String) strings of hyper links and to get the strings in between. The found candidate strings are additionally checked for specific suffixes fromSupported Suffixesas well as for obviously invalid file names (for example finishing slash or containing “*” or “?” characters) to download only desired file types. This is a weak approach which may not work fine for a number of web pages, however, for many simple sites it works out of the box.If the web site finds files located in other directories than the one of the website,
DirectoryDownloaderreplaces forwards and backward slashes with underscores “_” and stores them with this file name inDestination Directory.Downloading the web page containing the web “directory” is downloaded synchronously, thus its download locks the application GUI a while. Thus ensure that
Remote Directory Check Intervalis not too small.Downloading found files is done asynchronously in the background and the GUI is updated after completing or interrupting each of them. Therefore this does not affect the responsiveness very much.
Web/html pages are usually transferred via the HTTP or HTTPS protocol. Currently other protocols (such as ftp) are not supported.
There is still no explicit authentication support implemented.
Windows¶
Default Panel¶
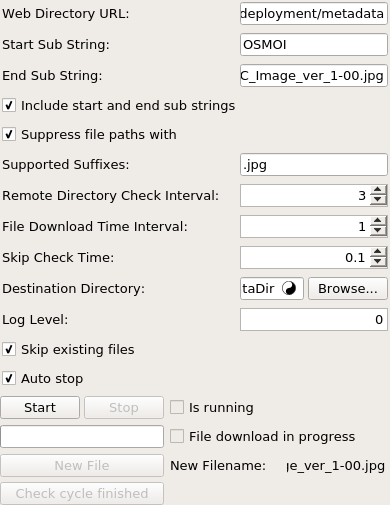
Parameter Fields¶
Field Index¶
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
Visible Fields¶
Web Directory URL¶
- name: webDirectoryURL, type: String¶
The URL of the web file “directory” which shall be parsed for (new) files.
Start Sub String¶
- name: startSubString, type: String, default: <a href="¶
A string which is searched as introducing string for file names to download, see Purpose for parsing details.
End Sub String¶
- name: endSubString, type: String, default: ">¶
A string which is searched as string which follows file names to download, see Purpose for parsing details.
Supported Suffixes¶
- name: supportedSuffixes, type: String¶
A number of space separated and case insensitive suffixes can be listed in
Supported Suffixeswhich shall be downloaded fromWeb Directory URL. LeavingSupported Suffixesempty will download all files even if they have no suffixes.
Include Start And End Sub Strings¶
- name: includeStartAndEndSubStrings, type: Bool, default: FALSE¶
If disabled, then
Start Sub StringandEnd Sub Stringare not included in the paths to be determined from the analyzed web page. If enabled they are inserted also in the path.
Suppress File Paths With¶
- name: suppressFilePathsWith, type: String, default: "<>¶
Some characters (such as inverted commas, smaller or larger characters etc) are technically allowed in file names, however, when they appear in parsed file paths they probably indicate wrongly detected files. Thus parsing results are usually better if file names containing them are not allowed. If listed here, paths containing them will be suppressed.
Remote Directory Check Interval¶
- name: remoteDirectoryCheckInterval, type: Float, default: 60, minimum: 0.1, deprecated name: checkTimeInSeconds¶
The time in seconds between two check for new files in the remote directory. Should not be too short to avoid high work load.
File Download Time Interval¶
- name: fileDownloadTimeInterval, type: Float, default: 5, minimum: 0.1¶
The waiting time in seconds before a file download is started.
Skip Check Time¶
- name: skipCheckTime, type: Float, default: 0.5, minimum: 0.05¶
If
Skip Existing Filesis checked then this is the waiting time in seconds between skipping the download of an existing file and the check for the download of another file. This allows a certain time between two file checks which allows user interaction with the application. IfSkip Existing Filesis not checked thenSkip Check Timeis deactivated.
Destination Directory¶
- name: destinationDirectory, type: String¶
The directory where the matching files in
Web Directory URLshall be stored; the directory must exist or error will occur.
Start¶
- name: start, type: Trigger¶
Manually starts checking
Web Directory URLfor files and downloads them intoDestination Directory.
Stop¶
- name: stop, type: Trigger¶
Stops checking
Web Directory URLfor new files.
Log Level¶
Auto Stop¶
- name: autoStop, type: Bool, default: TRUE¶
If checked then
Stopis automatically performed after the full found file list has been downloaded. OtherwiseWeb Directory URLwill regularly be checked for new files.
Skip Existing Files¶
- name: skipExistingFiles, type: Bool, default: TRUE¶
If checked then a file already existing in
Destination Directorywill not be downloaded; if not checked it will be overwritten silently.
Is Running¶
- name: isRunning, type: Bool, persistent: no¶
Output only: enabled if the module currently runs checks of
Web Directory URLfor new files eachRemote Directory Check Intervalor disabled otherwise.
File Download In Progress¶
- name: fileDownloadInProgress, type: Bool, persistent: no¶
Output only: checked if a file is currently downloaded, otherwise not checked.
New Filename¶
- name: newFilename, type: String, persistent: no¶
Output only: the full path of the most recently downloaded file or empty otherwise.
New File¶
- name: newFile, type: Trigger¶
Output only: triggered if a new file has been downloaded successfully and whose full path is available in
New Filename.
Check cycle finished¶
- name: checkCycleFinished, type: Trigger¶
Trigger field which is notified after each file check cycle regardless of any downloaded file or successful download.